

Best Practices for Secure Open-Source/Proprietary Software Development
Introduction
As developers, it is crucial to prioritize security in our software development process. Vulnerabilities in open-source software can have far-reaching consequences, impacting users and systems worldwide. This enhanced security advisory aims to provide you, the developers, with important information and best practices to mitigate vulnerabilities and ensure the safety of your codebase. By following these guidelines, we can contribute to a more secure open-source and proprietary technology ecosystem.
1. Understanding Vulnerabilities
- Familiarize yourself with common software vulnerabilities, such as injection attacks, cross-site scripting (XSS), cross-site request forgery (CSRF), and insecure direct object references (IDOR).
- Injection attacks: Understand the risks associated with user input that can be executed as code and implement input validation and sanitization techniques.
- XSS: Learn about the dangers of unvalidated user input and adopt output encoding techniques to prevent malicious script execution.
- CSRF: Recognize the impact of forged requests and implement measures like anti-CSRF tokens to protect against this attack vector.
- IDOR: Understand the implications of direct object references and implement access controls and authorization mechanisms to ensure data integrity.
- Stay updated with vulnerability trends and use common vulnerability metrics like the Common Vulnerability Scoring System (CVSS) and Common Weakness Enumeration (CWE) to evaluate and prioritize the risk, impact, and severity of vulnerabilities.
- Regularly monitor security news and vulnerability databases to stay informed about emerging threats and recent exploits.
- Utilize CVSS and CWE to assess vulnerabilities, determine their severity, and prioritize remediation efforts based on their potential impact on your software.
2. Secure Coding Principles
- Apply secure coding principles, including input validation, output encoding, proper authentication and authorization mechanisms, secure session management, and secure error handling.
- Validate and sanitize user input to prevent injection attacks and ensure the integrity of your data.
- Employ output encoding techniques to mitigate the risk of XSS vulnerabilities and protect users from malicious content.
- Implement strong authentication and authorization mechanisms to enforce access controls and prevent unauthorized actions.
- Maintain secure session management practices, such as session expiration, secure cookie handling, and protection against session fixation attacks.
- Implement robust error handling mechanisms to prevent the exposure of sensitive information and avoid information leakage.
- Implement secure coding practices to mitigate the risk of common vulnerabilities, such as SQL and OS command injections, XSS, and CSRF attacks.
- Use prepared statements or parameterized queries to prevent SQL injections and ensure the safety of database interactions. Avoid constructing OS commands with user input directly and utilize safe APIs or libraries to prevent OS command injections.
- Apply input validation and output encoding techniques to prevent XSS attacks and protect users from malicious scripts. Implement anti-CSRF measures, such as unique tokens, to validate the origin of requests and prevent cross-site request forgery.
- Regularly review and refactor your codebase to address potential vulnerabilities and ensure adherence to secure coding standards.
- Conduct thorough code reviews to identify potential vulnerabilities, adherence to secure coding practices, and identify areas for improvement.
- Refactor code to eliminate security weaknesses, improve code quality, and ensure adherence to secure coding standards.
- Establish a process for ongoing vulnerability assessment and code maintenance to identify and address security issues in a timely manner.
3. Version Control and Secure Packaging
- Utilize version control software, such as Git, to track and manage changes in your codebase effectively.
- Leverage version control systems to track changes, collaborate with team members, and maintain a history of code modifications.
- Use branching and merging strategies to manage concurrent development and ensure code stability.
- Follow secure versioning schemes to ensure the accurate identification and tracking of vulnerabilities, patches, and updates.
- Adopt a clear and consistent versioning scheme that allows easy identification of security patches, bug fixes, and new releases.
- Communicate versioning changes effectively to users and maintain a changelog that highlights security-related updates.
- Maintain a robust packaging ecosystem, leveraging tools like npm, Maven, PyPI, and nuget, and keep your dependencies up to date to avoid known vulnerabilities in third-party libraries.
- Regularly update dependencies to incorporate security patches and bug fixes provided by the library maintainers.
- Monitor vulnerability databases and security advisories related to your dependencies and act promptly to mitigate any identified vulnerabilities.
- Consider using dependency management tools to automate the process of keeping dependencies up to date and ensuring the use of secure versions.
4. Vulnerability Analysis and Documentation
- Contribute to the curation of a comprehensive security advisory database by analyzing, verifying, and documenting vulnerability reports.
- Collaborate with the Security Lab to analyze and verify vulnerability reports, ensuring their accuracy and reliability.
- Document the details of vulnerabilities, including their impact, affected products or versions, and potential mitigation strategies.
- Ensure the completeness, correctness, and consistency of the advisory data within the existing security database.
- Perform thorough quality checks on the advisory data, ensuring all necessary information is included and accurately documented.
- Maintain consistency in the format and structure of the security advisories to facilitate easy consumption by developers and security professionals.
- Curate and publish security advisories, including detailed descriptions, affected product data, severity assessments, and recommended mitigation strategies using our curation tooling.
- Use the curation tooling provided to publish comprehensive security advisories that assist developers in understanding the vulnerabilities and taking appropriate actions.
- Include detailed descriptions of vulnerabilities, impacted products or versions, severity assessments, and practical steps to remediate the vulnerabilities.
5. Community Engagement and Knowledge Sharing
- Engage and collaborate with online communities dedicated to open-source security and development.
- Participate in forums, discussion groups, and mailing lists focused on open-source security to share knowledge, ask questions, and learn from others.
- Contribute to open-source projects by reporting vulnerabilities, submitting patches, and engaging in constructive discussions with the community.
- Foster a culture of knowledge sharing and collaboration by actively participating in discussions, forums, and open-source projects related to security and vulnerability management.
- Share your expertise and experiences with the community, contributing to the collective knowledge and improving the security practices within the open-source ecosystem.
- Encourage and support other developers in adopting secure coding practices and understanding the importance of vulnerability management.
- Contribute to the growth and improvement of the open-source ecosystem by sharing your expertise, experiences, and best practices.
- Write technical articles, blog posts, or documentation to educate developers on secure coding practices, vulnerability management, and open-source security.
- Conduct workshops or webinars to disseminate knowledge and promote secure development practices within the open-source community.
6. Emerging Trends
As targeted attacks at code and private data continue to more sophisticated, adopting these developer best practices is crucial for ensuring the security and reliability of software systems. By implementing the following key points, developers can significantly enhance the overall development process and mitigate potential risks:
- Peer Review: Encouraging peer code reviews helps identify coding flaws, logic errors, and potential vulnerabilities early in the development lifecycle. Collaborative feedback and knowledge sharing among team members lead to improved code quality and security.
- CI/CD Pipeline: Implementing a robust Continuous Integration and Continuous Deployment (CI/CD) pipeline enables automated testing, builds, and deployment. It ensures that code changes are thoroughly tested and reviewed before being deployed, reducing the likelihood of introducing vulnerabilities or breaking the system.
- Separation of Duties: Enforcing separation of duties ensures that different individuals or teams are responsible for specific stages of the development and deployment process. This helps prevent unauthorized access, limits the potential for insider threats, and improves accountability within the development team.
- Data Protection and Backup: Implementing regular backups, disaster recovery plans, and data protection measures safeguards against data loss, system failures, and potential security breaches. It is essential to have reliable backup mechanisms and recovery procedures in place to quickly restore systems and minimize downtime.
- Cybersecurity: Prioritizing cybersecurity throughout the development lifecycle helps safeguard against external threats and potential vulnerabilities. This includes implementing secure coding practices, staying updated with the latest security patches, conducting regular security assessments, and maintaining awareness of emerging threats and best practices.
Conclusion
By integrating these best practices into their development workflows, developers can enhance the security, reliability, and maintainability of their software systems, ultimately providing better experiences for end-users and reducing the risk of security incidents.
As developers, we hold the responsibility to build secure and resilient software. By adhering to the best practices outlined in this enhanced security advisory, you can contribute to the creation of a safer development environment. Remember, your commitment to secure coding principles, vulnerability analysis, and active community engagement will help protect users and systems from potential threats. Let’s work together to ensure the integrity and security of open-source software development.

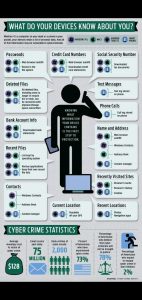




 – Cheatsheet")


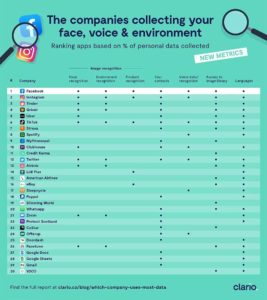 Source:
Source: 





